Быстрая генерация кода ИИ-агентами ведет к инвестициям в автоматизированные проверки для ускорения верификации
Проверка становится быстрой и автоматической; harness заменяет человеческое ревью как основной источник корректности в масштабе; человек переключается на разработку проверок вместо чтения каждой строки кода
Видео-источник
Быстрая генерация кода ИИ-агентами ведет к инвестициям в автоматизированные проверки для ускорения верификации
Связка 1
Начальное состояние: AI-агенты генерируют код быстрее, чем любая команда способна его проверить; узким местом стало доверие к написанному коду
Преобразование: Datadog внедряет подход harness-first engineering: инвестиции в автоматизированные проверки (DST, формальные спецификации, теневая оценка, циклы обратной связи на основе наблюдаемости), которые могут за секунды определить корректность кода, генерируемого агентом
Конечное состояние: Проверка становится быстрой и автоматической; harness заменяет человеческое ревью как основной источник корректности в масштабе; человек переключается на разработку проверок вместо чтения каждой строки кода
AI-агенты теперь могут создавать программное обеспечение быстрее, чем любая команда способна его проверить. Узкое место сместилось с написания кода на доверие к написанному.
Мы уже видели такую закономерность раньше. Ранние программисты сопротивлялись компиляторам, потому что могли написать лучший ассемблер вручную. Часто они были правы. Компиляторы заслужили доверие, потому что языки, которые они транслируют, имеют точную семантику: программист определяет, что делает программа; компилятор имеет свободу в том, как это реализовано. Автоматизация неизменно побеждала только в сочетании с верификацией.
С AI-агентами построение доверия сложнее, чем в случае с компиляторами. AI-агенты поглощают неограниченный естественный язык, иногда из ненадёжных источников, и переводят его в работающий код. Мы должны найти новые способы проверки результатов этих новых движков синтеза программ.
В Datadog мы видим в этом свою возможность: предотвратить переход от «vibe-coding» к «yolo-deploys». Наш подход — harness-first engineering: инвестиции в автоматизированные проверки (DST, формальные спецификации, теневая оценка, циклы обратной связи на основе наблюдаемости), которые могут за секунды определить корректность кода, генерируемого агентом. Вместо чтения каждой строки кода, сгенерированного агентом, инвестируйте в автоматизированные проверки, которые могут с высокой уверенностью за секунды сказать, корректен ли код. Агент генерирует код, harness проверяет его, производственная телеметрия подтверждает, и если что-то не так, обратная связь обновляет harness, и агент пробует снова. Конкретные методы разработки harness различаются по строгости — детерминированное симуляционное тестирование, формальные спецификации, теневая оценка, циклы обратной связи на основе наблюдаемости — но принцип остаётся тем же: сделать проверку быстрой и автоматической, и пусть harness делает ту работу, с которой человеческое ревью не может справиться в масштабе.
Мы строили это видение в течение последнего года. BitsEvolve, наш эволюционный оптимизатор на основе LLM, использует циклы обратной связи, управляемые продакшеном, чтобы эволюционирующий код оставался корректным. Он обеспечил ускорение в 10 раз на ключевых функциях приёма данных, в 1,53 раза на кодировщике DeBERTa для сканера конфиденциальных данных и в 1,57 раза на Toto, нашей модели прогнозирования временных рядов — всё проверено на живом трафике. Мы поняли, что если обвязка достаточно надёжна, LLM может свободно исследовать, и результаты сохраняются. Хорошая обвязка делает итерации дешёвыми. Слабую обвязку нельзя компенсировать лучшими моделями или большим количеством человеческих ревью.
Затем в конце 2025 года мы наблюдали резкий скачок возможностей моделей. До этого BitsEvolve работал на уровне файлов и функций. Мы начали задаваться вопросом, что произойдёт, если применить подход «сначала обвязка» к целым системам. Этот пост — первый в серии, в которой мы описываем, как мы развили инженерию «сначала обвязка» до масштаба системы.
В этом первом посте мы рассматриваем два проекта: redis-rust, где мы изучали методологию методом проб и ошибок, и Helix, потоковый движок, совместимый с Kafka, где мы её доработали. В обоих случаях обвязка оказалась достаточно сильной, чтобы заменить ревью кода как основной источник корректности: redis-rust достиг продакшен-подобного стейджинга с сопоставимой задержкой и снижением памяти на 87% после итераций под руководством агента, а Helix выдержал миллионы детерминированных симуляционных прогонов и достиг около 93% пиковой пропускной способности диска, не жертвуя гарантиями семантики Kafka. Закономерность была последовательной: как только инварианты становились явными и постоянно проверялись, агент мог безопасно двигаться быстрее, чем люди могли бы проверять.
redis-rust: Изучение методологии
redis-rust была нашей первой попыткой заставить кодирующего агента построить полноценную систему. Мы запустили её с одним агентом (Claude Code с Opus 4.5) и учились в основном, обнаруживая проблемы по мере развития кодовой базы.
В течение нескольких часов обсуждения архитектурных идей — дизайн «актор на шард», конфликтно-свободные реплицируемые типы данных (CRDT) — агент создал рабочий Redis-совместимый сервер. Он скомпилировался и прошёл тесты, но многие детали были тонко неправильными так, что у нас изначально не было инфраструктуры для их обнаружения. Сообщения об ошибках отклонялись от совместимости с Redis способами, которые казались разумными, но были неверными. Агент также имел склонность к излишней инженерии абстракций, которые мы позже упростили.
Поэтому мы начали строить шаги верификации слой за слоем. Каждый слой был мотивирован чем-то, что проскочило через слой ниже.
Мы начали с оракула теневого состояния: простой HashMap, работающий параллельно с реальным исполнителем, который сравнивал ответы после каждой операции. Это ловило базовые семантические ошибки, но не могло проверить пути, зависящие от времени, поэтому мы добавили детерминированное симуляционное тестирование (DST) с внедрением сбоев.
DST требовал инвариантов для проверки, что привело нас к написанию спецификаций TLA+ для протоколов репликации и сплетен. Для свойств слияния CRDT нужны были математические гарантии, поэтому мы добавили Kani, инструмент верификации Rust, для ограниченных доказательств. Для корректности на уровне системы мы запускали Maelstrom, фреймворк тестирования распределённых систем, с проверкой линеаризуемости Knossos на 1, 3 и 5 узлах. Мы также запустили официальный набор тестов совместимости Redis Tcl для реализованных команд. Проектные решения, компромиссы и методы верификации задокументированы в техническом отчёте.
Следующим шагом стала эмпирическая верификация с использованием реального трафика. Мы использовали Ephemera, нашу внутреннюю систему кэширования, которая управляет кластером шардов Redis через API плоскости данных/управления. Для корректного сравнения мы настроили теневой кластер redis-rust, который получал ту же нагрузку, что и его аналог Redis 8.4.
Результаты
Используя pup в качестве интерфейса Datadog, агент подтвердил, что redis-rust работает в staging-среде с незначительными различиями в задержках:
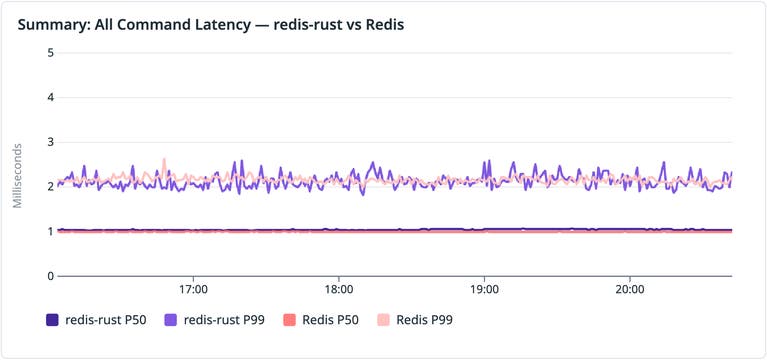
Профиль задержек redis-rust изначально был сопоставим с Redis.
Однако он использовал в 8 раз больше памяти, чем Redis 8.4, поскольку был жестко запрограммирован на предварительное выделение 512 буферов по 8 КБ (4 МБ) при запуске, оптимизированных для исчерпывающего микро-бенчмарка, среди прочего. В течение нескольких минут агент предложил и реализовал три оптимизации для снижения потребления памяти на 87%:
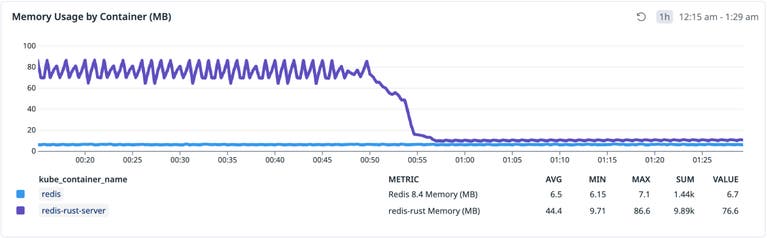
Оптимизация памяти агентом с использованием метрик в качестве обратной связи.
Мы продолжим настройку производительности, используя метрики памяти, сети и задержек, а также профили CPU.
Helix: Улучшение через обвязку
Helix — это стриминг-сервис, похожий на Kafka, работающий на объектном хранилище. Это ещё одна полная система, которую мы построили с помощью агентов кодирования, основываясь на опыте redis-rust. На этот раз мы работали с несколькими агентами кодирования, в основном Claude Code и Codex. Рабочий процесс был ориентирован на ограничения: артефакты проектирования — это контракты, семантика явно задана (используя наш более чем десятилетний опыт эксплуатации Kafka), и каждый артефакт связан с механизмом обратной связи через пирамиду верификации, которая может опровергнуть ошибки.
Пирамида верификации
Каждый уровень обеспечивает компромисс между скоростью и строгостью:
| Уровень | Инструмент | Время | Уверенность |
|---|---|---|---|
| Символический | Спецификации TLA+ | 2 мин чтения | Понимание |
| Основной | DST | ~5 с | Высокая |
| Исчерпывающий | Проверка моделей (Stateright) | 30–60 с | Доказательство |
| Ограниченный | Ограниченная верификация (Kani) | ~60 с | Доказательство (ограниченное) |
| Эмпирический | Телеметрия + бенчмарки | секунды–минуты | Истина на практике |

Общие инварианты перетекают из спецификаций TLA+ в Stateright, DST, Kani и телеметрию staging, при этом DST является основным уровнем верификации.
Контракты до кода
Мы заранее описали ключевые инварианты — реплицированный лог плюс объектное хранилище, модель партиций, границы отказов, совместимость с Kafka — а затем поручили агенту спроектировать каждую подсистему независимо: Raft (верифицирован с помощью TLA+), журнал упреждающей записи (WAL), многоуровневое хранение, DST, сервисный слой, проводной протокол Kafka. Агенту не разрешается изобретать смысл системы. Что является долговечным по сравнению с подтверждённым? Что зафиксировано по сравнению с видимым? Что происходит при сбое на каждой границе?
Antithesis и AWS называют это «полуформальными методами»: спецификации и инварианты достаточно явные, чтобы их можно было проверить, и достаточно дешёвые, чтобы выполняться непрерывно. Умственные затраты примерно в 2–3 раза превышают усилия по написанию самого кода.
Это окупается немедленно — явные инварианты превращают каждую итерацию агента в объективное решение «пройдено/не пройдено», а не в оценочное суждение.
DST — рабочая лошадка. Популяризированный FoundationDB и TigerBeetle, DST абстрагирует физическое время, делает выполнение детерминированным и синтетически внедряет сбои. Каждый запуск занимает около 5 секунд и проверяет реальный продакшн-код через рандомизированные сценарии с внедрением сбоев.
Спецификации TLA+ предоставляют карту. Они определяют переменные состояния, действия и инварианты, которые иначе потребовали бы часов на извлечение из кода реализации. Мы генерируем их из записей архитектурных решений (ADR), выявляя неоднозначности на раннем этапе. Проверка моделей и Kani подключаются, когда требуются более строгие гарантии. Телеметрия эмпирически подтверждает всё. Сначала используется самый лёгкий механизм, способный опровергнуть гипотезу.
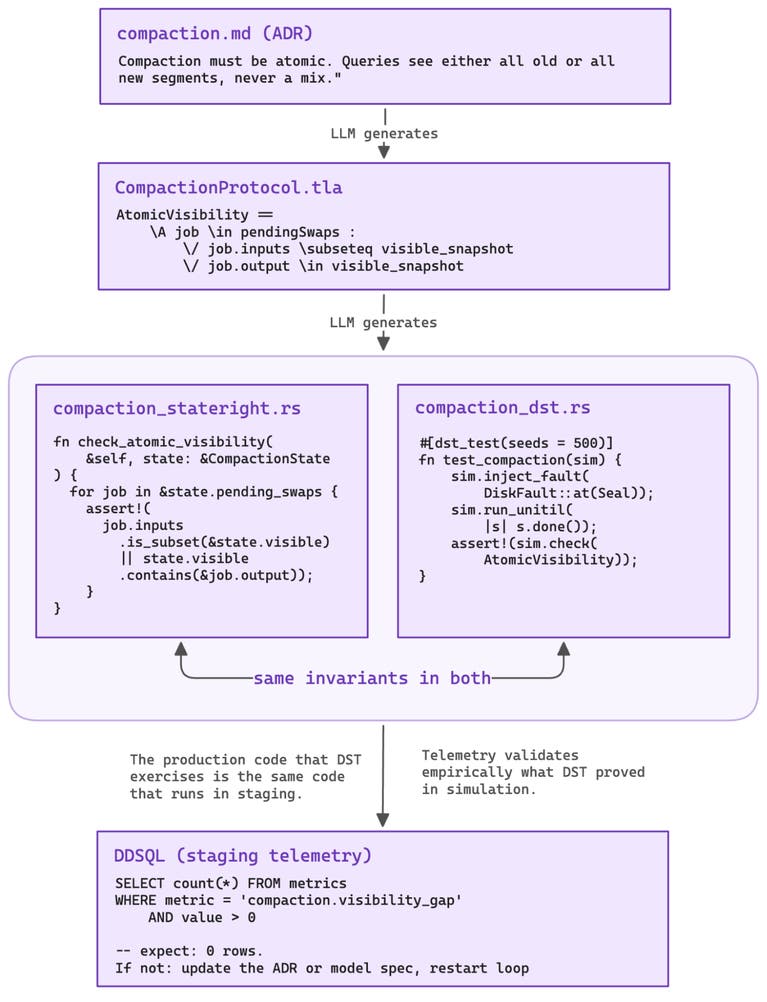
Записи архитектурных решений (ADR) генерируют спецификации TLA+, которые определяют инварианты, повторно используемые в Stateright, DST, Kani и телеметрии на этапе развёртывания, чтобы поддерживать согласованность уровней верификации.
Цикл обратной связи DST
Первоначальная реализация агента компилировалась и проходила модульные тесты, но ей не хватало строгости. Нам пришлось пойти дальше, чтобы добиться детерминированной валидации: исчерпывающие проверки свойств, явные инварианты и настраиваемое внедрение сбоев на уровне сети, диска и узла. Мы использовали технику BUGGIFY, чтобы намеренно расширить окно, в котором могут вмешиваться конкурентные операции.
Мы объединили это с тестированием на основе свойств: метаморфические свойства, свойства roundtrip (например, decompress(compress(bytes)) == bytes) и дифференциальное тестирование — методы, которые нашли сотни ошибок в GCC и использовались для проверки AWS Cedar.
Нашей целью было 500 сидов DST на компонент. Детерминированные сиды делают сбои воспроизводимыми: агент воспроизводит точную последовательность и отслеживает нарушение инварианта до строки кода, которая его вызвала.
Например, DST выявил ошибку WAL, при которой усечение в памяти происходило до синхронизации на диске. Внедренный сбой диска означал, что сегмент никогда не повторялся, что приводило к потере данных. Исправлением стала копия при записи. Очевидно, как только симуляция указывает на это. Легко пропустить при ревью.
Эти ошибки проявляются только при определенном времени сбоя. Модульные тесты их не находят. Ревью кода может, в удачный день. DST ловил их детерминированно, за секунды.
Когда-то мы были зелёными на 500 сидов на компонент, мы масштабировались до 10 миллионов сидов на все компоненты, затем до системной интеграции с инвариантами семантики Kafka: каждое подтверждённое сообщение должно быть потребляемо, смещения потребителей должны монотонно возрастать, а смена лидера не должна приводить к потере записей.
Производительность: восхождение на холм со страховкой
И в redis-rust, и в Helix, когда корректность была зафиксирована, работа над производительностью превратилась в контролируемое восхождение на холм. Агент предлагает оптимизацию, запускается полный набор DST; если тесты проходят, мы измеряем пропускную способность и оставляем изменение. Если тесты падают, мы откатываем. Эмпирический пример в redis-rust: агент нашёл оптимизации CPU на основе данных профилирования, но в итоге сломал тест на линейзуемость одного узла.
Для Helix агент начал с zero-copy обработчиков и устранения конкуренции, затем предложил более значительные изменения: конвейеризацию Raft, буферизованный WAL и, в конечном итоге, архитектуру на основе акторов. Переход к дизайну на основе акторов был решением человека. День спустя мы достигли примерно 93% пиковой пропускной способности диска (измерено с помощью fio), при этом все тесты DST по-прежнему проходили.
Что на самом деле сделал человек
В обоих проектах роль человека была узкой, но значимой: определить идею системы и инварианты, проверить и усилить тестовую среду DST, установить измеримые цели и утвердить архитектурные изменения.
Всё остальное — разработка проектов, реализация компонентов, исправление ошибок DST, оптимизация пропускной способности — выполнял агент, работая с тестовой средой.
Результаты
Мы интегрировали Helix в нашу staging-среду с внутренним streaming control plane. Для этого потребовались небольшие дополнения в конфигурацию развертывания Helix. Благодаря этому клиенты streaming-платформы могут прозрачно отправлять и получать данные через Helix.
Helix, работающий как совместимая с Kafka замена за нашей внутренней streaming-абстракцией.
Затем мы пошли дальше и смогли использовать один кластер Helix (группа Raft из трех узлов) для хранения и обслуживания потока данных профилирования, примерно 10 000 сообщений в секунду, обеспечивая работу APM-профилирования в нашей staging-среде.

Один кластер Helix, обслуживающий поток данных APM-профилирования в нашей staging-среде.
Для рабочей нагрузки потока данных профилирования мы наблюдали значительное улучшение задержки отправки, измеренной клиентом streaming-платформы. Отправка в Helix в среднем составляла 22,2 мс по сравнению с 116 мс для базового кластера Kafka.
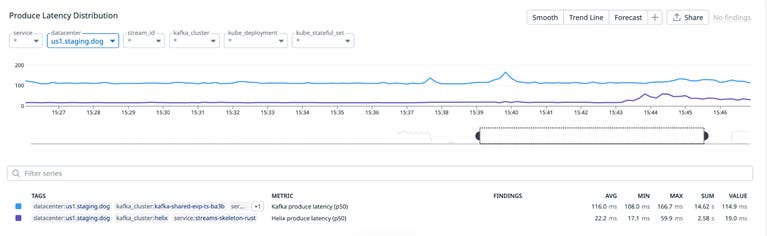
Сравнение p50 задержки отправки для потока APM-профилирования между Helix и базовым кластером Kafka.
Инверсия масштабируемости
Helix невозможно было бы построить, используя ревью кода как основной метод верификации. Агент генерировал слишком много итераций, слишком быстро:
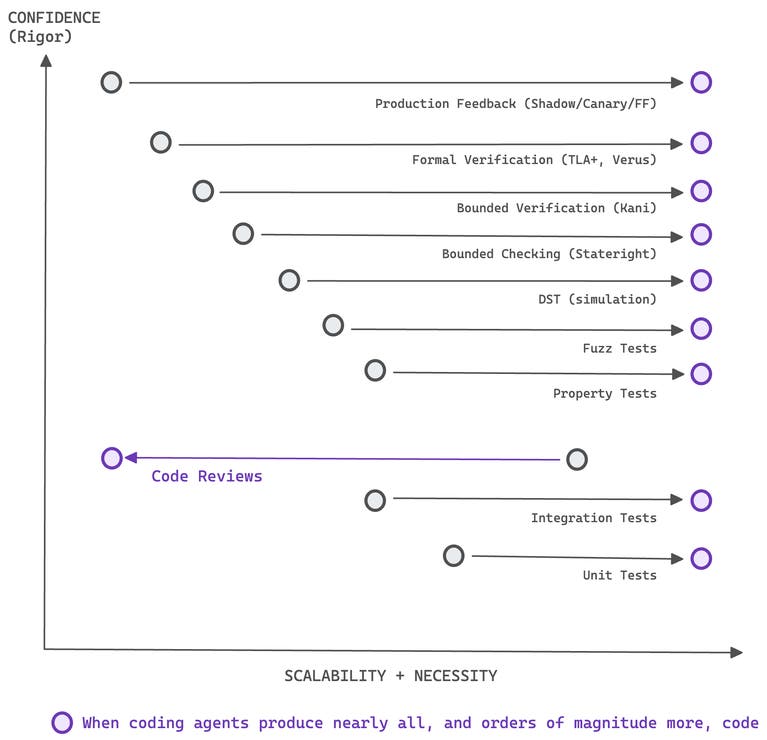
Методы верификации, ранжированные по масштабируемости и строгости, показывающие, как кодирующие агенты инвертируют традиционный компромисс между формальными методами и ревью кода.
До появления агентов ревью кода было самым масштабируемым методом верификации. Каждая команда уже его использует. Формальная верификация была наименее масштабируемой — дорогой, специализированной и исторически оправданной только для критически важных систем с высоким периодом полураспада, где отказы имели серьезные последствия.
Antithesis формулирует это как компромисс между масштабируемостью и строгостью. Мы адаптировали эту формулировку, чтобы показать, что меняется, когда в игру вступают кодирующие агенты. Экономика инвертируется. LLM может генерировать спецификации TLA+, писать обвязки DST и запускать доказательства Kani как часть своего итерационного цикла, превращая то, что раньше было многомесячными инвестициями, в автоматизированные этапы пайплайна.
Ревью не устарели. Роль человека меняется, так же как другие инженерные дисциплины развивались со временем. Строители мостов перестали проверять каждую заклепку, когда разработали нагрузочное тестирование. Металлурги перестали оценивать каждую партию на глаз, когда получили спектрометры. Экспертиза переходит от проверки результата к разработке проверок.
Во всех проектах, построенных таким образом, мы обнаружили, что время, которое мы потратили бы на ревью каждого аспекта сгенерированных агентом изменений, было лучше потрачено на укрепление обвязки — ужесточение инвариантов, расширение покрытия симуляций и подключение циклов обратной связи телеметрии.
Обвязка накапливается так, как не может ревью кода. Каждый добавленный инвариант ловит целый класс ошибок в будущих итерациях, а не только текущие изменения. С обвязкой ревью кода становятся фильтрами Блума — быстрым шлюзом, а не источником корректности. То, что читает ревьюер, — это не изменения, а вывод обвязки: какие инварианты прошли, какие сиды были протестированы, что подтвердила телеметрия. Меньше похоже на чтение кода, больше на чтение EXPLAIN ANALYZE.
Helix, redis-rust и несколько более крупных экспериментов — некоторые достигали 300 000 строк кода — по-прежнему оставляли человека в цикле. Человек разрабатывал обвязку, задавал цели и утверждал архитектуру.
Агенты итерировали на его основе.
Куда это ведет
Везде, где свойство может быть проверено автоматически — с помощью тестов, доказательств, симуляций, измерений — больше ответственности можно делегировать агенту. Там, где это невозможно, человек остается в контуре. Мы называем это границей верификации.
Очевидное возражение: что происходит, когда сама обвязка ошибочна? Неполные инварианты могут создать автоматическую уверенность в некорректном поведении. Здесь наблюдаемость замыкает цикл. Производственная телеметрия — метрики, логи, трейсы и траектории — поступает обратно в конвейер верификации, выявляя несоответствия между смоделированным поведением и реальным выполнением, позволяя нам со временем уточнять обвязку. Без наблюдаемости цикл не замкнут. Мы еще в начале пути, но направление кажется верным: люди определяют работу и результаты, а обвязка определяет, как они достигаются.
Ценность формальных методов — не в самих инструментах. Это дисциплина выражения ограничений, которые точны, проверяемы машиной и однозначны. Свойства, которые генерирует агент, теневая оценка на деплоях и телеметрия, проверяющая поведение в продакшене — все это выражения инвариантного рассуждения на разных уровнях. С агентами меняется то, что все эти механизмы стало проще создавать и итерировать. Наш совет: инвестируйте в обвязку пропорционально цене отказа.
Когда обвязка зависит от наблюдаемости для замыкания цикла, платформа наблюдаемости становится уровнем управления для программного обеспечения, созданного агентами. Лучшие практики еще не написаны. Мы открываем их по ходу дела.
В Части 2 мы описываем Unicron × BitsEvolve — систему, где оракул корректности, бенчмарк производительности и песочница безопасности полностью автоматизированы, а человек полностью выходит из цикла.